
FAQ on Research Data Management

Why should I do RDM?
The correct and sustainable processing of research data is not only a necessary criterion in funding applications. A well-planned RDM also serves to simplify your own work: data is provided with context information (metadata) that can be used to quickly and precisely find the desired data. Correct storage allows you to "read" your data for more than ten years and to use it for further purposes and subsequent research questions.
Large funding organisations such as the DFG are increasingly expecting a statement on the planned handling of the research data to be expected in the project when submitting your applications. Scholarly journals are also increasingly expecting the supply of the primary data on which a publication is based.
When should I start?
You should deal with RDM as early as possible. In the case of third-party-funded projects, this means that you have to think about what data will accrue in your research project before and during the application process. Which data type (excel-, word-, access-files etc) is generated during the project? How big are the expected files? Do you need additional storage space? Do you need a platform that allows you to share data with other project partners? Do you need a data manager (e. g. in large collaborative projects) to support you in data processing?
For these conceptual considerations, you can orient yourself on the life cycle of research data. The creation of a data management plan at the beginning of a project can also help you to design a structured procedure for managing your data.
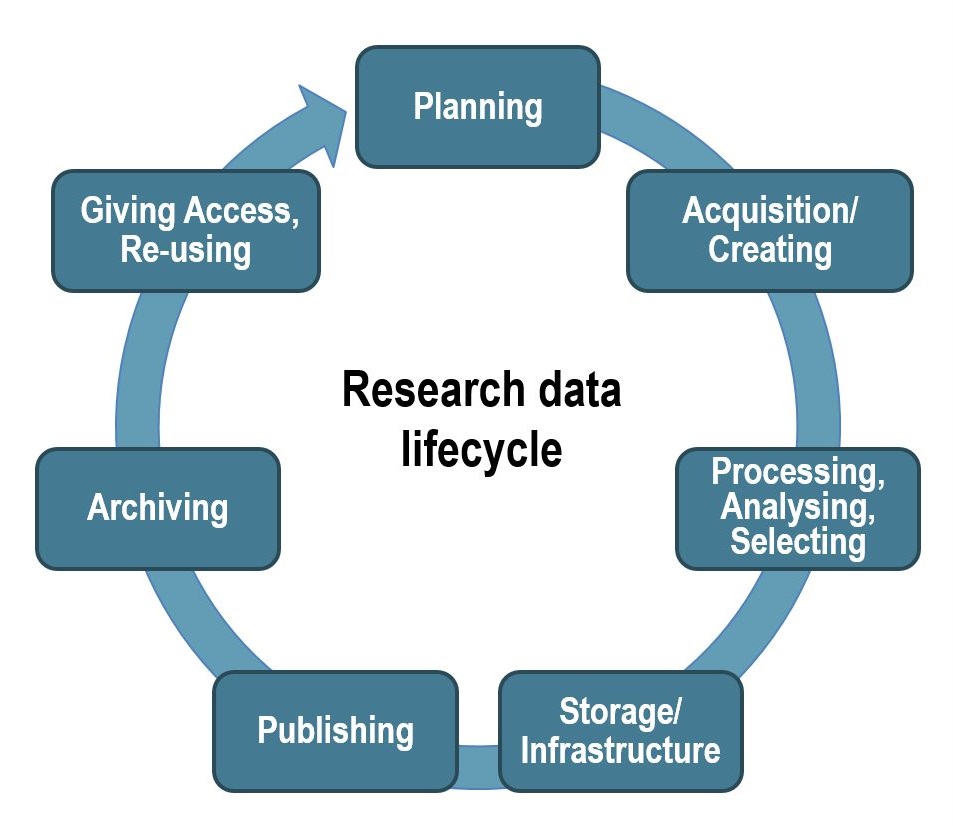{kind=link}
How do I write a Data Management Plan?
We offer you a simple Word DMP template in German and English, in which every aspect is explained and provided with a checklist for orientation.
Depending on the funding line, the samples of the Computer and Media Service of the HU Berlin for project proposals to the DFG or BMBF can also serve as helpful templates.
As a tool for the development and research of data management plans, C3RDM is currently preparing an institutional access to the Research Data Management Organiser (RDMO).
Where do I find research data for reuse?
If you would like to search for suitable and already published data for your research project or if you are looking for a repository for your data, we recommend that you first search via the portal re3data.org, which lists a large number of repositories. Depending on the discipline, it may also be worthwhile to search Data Journals, some of which are listed on the platform forschungsdaten.org.
What does FAIR mean in this context?
Research data are FAIR if they are findable, accessible (i.e. at least metadata can be accessed), interoperable and reusable.
The FDMentor project has summarized the FAIR principles in an illustrative poster and a detailed explanation of the FAIR principles can be found in the GO-FAIR initiative.
What are persistent identifiers?
In order to make research data searchable and reusable, a unique, persistent identifier is required, which is assigned to a data set or a digital object. In contrast to addressing or linking by a URL, a persistent identifier refers to content, not to a location on the Internet.
For research data, Digital Object Identifiers (DOI) are internationally known as persistent identifiers. The members of the DataCite e.V. association act as DOI allocation offices for research data. In Germany these are:
How do I publish my research data?
You can publish your research data in repositories or data journals. Some journals also offer the option of uploading the data associated with a publication to a journal's own repository. You can use the online data directory re3data to find the repositories most commonly used for your subject.
Scientists of the UzK are welcome to seek individual advice from the C3RDM team when searching for a suitable subject repository. Just send us an e-mail and we will get back to you as soon as possible!